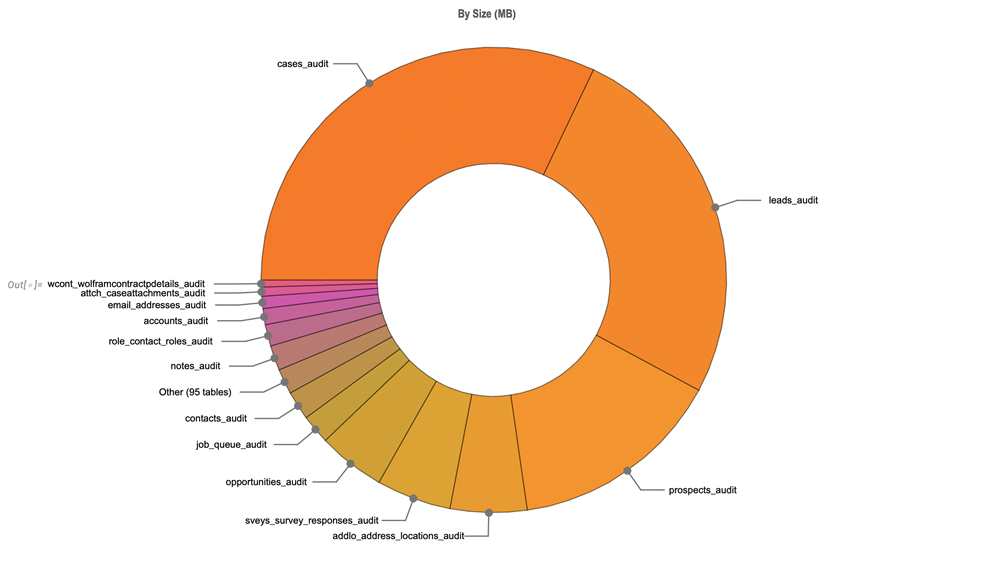
I have a lot of questions about Data Archiver and what happens in the backend when you archive a module's records without deleting the records.
I'll start with one scenario: Say I archive all Closed Cases created 5 or more years ago.
- Do the cases_audit entries get deleted or archived?
- Do the emails linked to the Case get archived? I would consider these "orphaned" if the case is gone.
- What happens to the relationships between Cases and other modules? Are they also archived?
- e.g do cases_bugs, accounts_cases, contacts_cases etc. for those cases get archived?
- What about attachments to case related Notes? is there an uploads_archive on the file system?
thanks,
FrancescaS