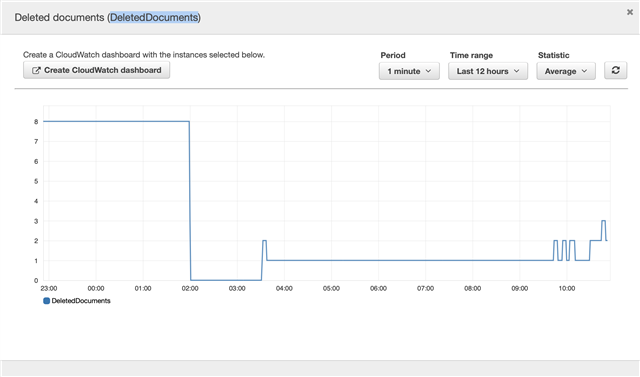
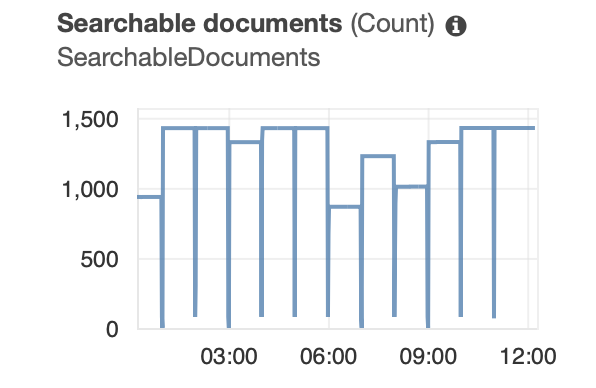
We have found that we occasionally end up with a situation where we search for new items and they don't come back in the search results. NOTE: Usually new things populate just fine, this only happens intermittently. We are able to fix the issue by running a system reindex from admin. We'd rather not have to do this manually and I see that there is a CLI command to reindex. Is it good practice to just run a system reindex using the CLI occasionally? How often, nightly? According to the documentation[1], this sounds like a not unusual occurrence, does that seem accurate to others?
[1] Performing a system index may resolve search issues for records that have been recently created or modules that were recently enabled for search