

We have hit a tipping point in world wide Emoji usage. We really must work like we live, because the perfect two character combination of pizza and beer and others like it are starting to appear in business emails and other business communications. In particular, marketers have started to use emojis in subject lines of emails as a way to catch people's attention.
As Rich Green put it:
It's nearing the end of the second decade of the third millennium.
If people want to use poop emoji's in business, so be it.
Many Sugar customers have started running into an issue with emojis when using MySQL databases or the Sugar cloud. What could be so challenging about a poop emoji, you may ask? For that you may need a quick lesson on Unicode.
Character encoding and the beginnings of Unicode
Many of you are programmers, so you likely know that computers run entirely on (binary) numbers. As you type away on your keyboard, the stream of characters that gets stored in memory is a sequence of numbers based on the character encoding in use. "A" could be stored as 65, while "a" could be stored as 97, and so on. Programmers are obsessed with efficiency, so they would create many different character encodings for different alphabets or character sets to only use as little space as possible.
This became a real challenge as we started to share documents between systems via e-mail or the world wide web. Identifying and using the right character encoding became very important and also very difficult. If you didn't know the character encoding then you had to guess and if you guessed wrong then the text would not be displayed properly at all.
Fortunately, a group of companies, organizations, and individuals decided to come together to form the Unicode consortium. The Unicode consortium's primary mission has been to standardize character encoding into the Unicode standard that is widely used today. The most common Unicode character encoding is UTF-8 which is a variable length character encoding that can store any Unicode code point (which includes a growing number of emojis) into a number that is 1 to 4 bytes long.
MySQL's utf8 and utf8mb4 encodings
Programmers are obsessed with efficiency. Many programmers will not use 4 bytes if they think 3 bytes will do. When MySQL first implemented UTF-8 years ago, they decided that supporting the Basic Multilingual Plane (BMP) was good enough since it contained all the characters and most symbols used in modern languages. These characters require no more than 3 bytes. Adding support for the Supplementary Multilingual Plane (SMP) which includes emojis would mean that some characters would need to be stored in 4 bytes, which was just one byte too many for somebody.
Whatever the reason, MySQL's first implementation of UTF-8 that they called utf8 did not fully support UTF-8. When they fully implemented UTF-8 years later, they called it utf8mb4. This has been a source of confusion for many years since MySQL's utf8 character set seems to work fine until you run into certain special characters like emojis. Trying to store an emoji in MySQL's utf8 results in failure and the loss of data.
Sugar Summer '18 migrates from utf8 to utf8mb4
Sugar Summer '18 will use utf8mb4 for MySQL. This will allow users to import and display records and emails that contain emoji and other characters in the SMP. This feature will also be rolled into a future on-premise release.
The Sugar Summer '18 release will be available for Sugar cloud customers in a few short weeks.
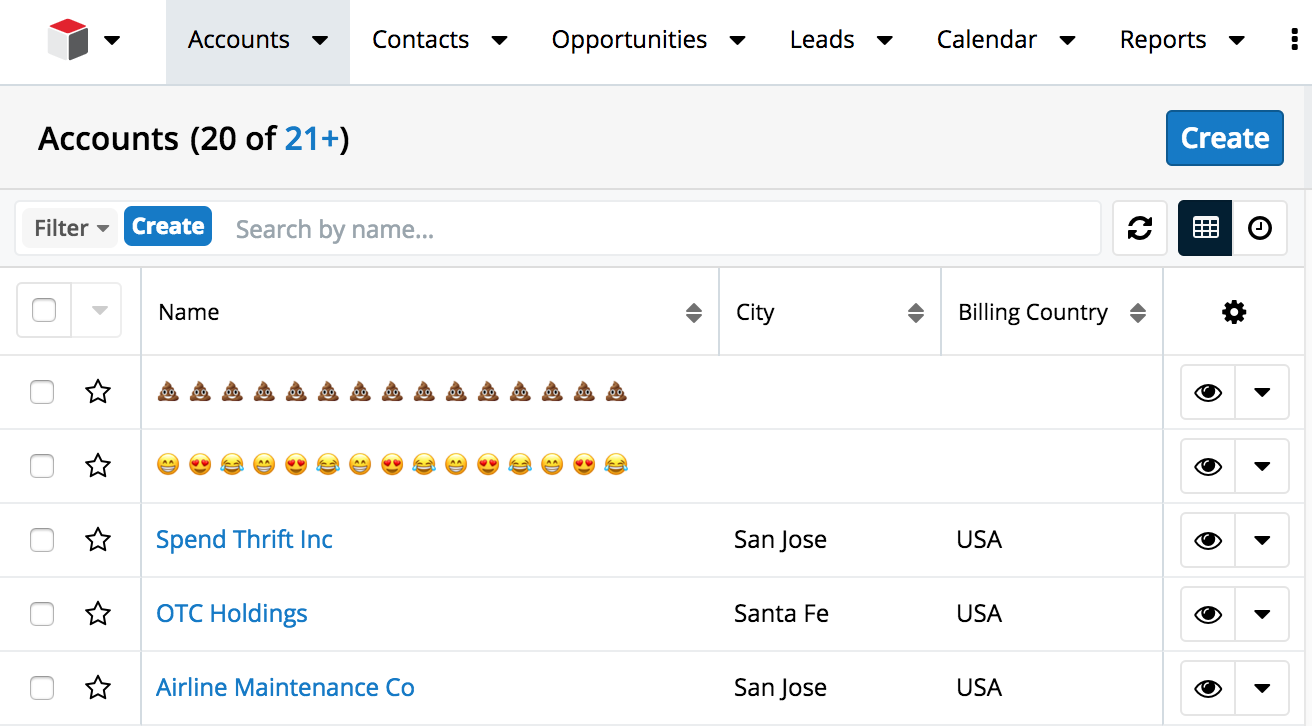
This character set and collation will be set automatically for new instances of Sugar and updated during the upgrade of existing instances of Sugar.
If you have changed the default DB collation and you are in the Sugar cloud or on-premise using a MySQL database, then you should ensure that your collation is utf8mb4 compatible prior to upgrade. The collation can be set by the admin in Admin > Locale > Collation or by modifying config_override.php. If your collation is utf8mb4 compatible, the upgrade will automatically migrate the collation to utf8mb4. For example, if you have set your collation to be utf8_swedish_ci, the upgrade will migrate the collation to utf8mb4_swedish_ci. If no collation is set, Sugar will use the default utf8mb4_general_ci.
Database tables with very large row sizes (for example, custom tables with a large number of custom fields) may be unable to be automatically upgraded. The upgrader will notify you if a table would exceed the single-row size supported by MySQL (65,535 bytes) upon conversion to utf8mb4. In order to reduce the row size, we recommend the following:
- Remove any/all fields that are not being used.
- Reduce the lengths for char/varchar fields (e.g. size of longest existing value plus some padding).
- Replace large varchar fields with text fields. Text fields are roughly 10 bytes, so significant size reduction exists when text fields can replace large varchar fields (e.g. VARCHAR(255).
