

On Dec 6th, we held our monthly office hours session on doing local Sugar development using Docker containers. A sort of continuation from our session last month on using Demo Builder for development.
Our own Rafael Fernandes was the expert this time around. He has extensive experience with Docker and with helping developers in our community get up and running with local Sugar development environments. Thanks Rafa!
Session Highlights
Introduction to SugarDockerized
SugarDockerized is a great resource to help developers get a working local development environment of Sugar up and running quickly and easily. Rafael Fernandes gave a live demonstration of building a local development environment from scratch - from installing Docker Desktop to downloading and starting the containers, to installing and testing Sugar running on his local machine.
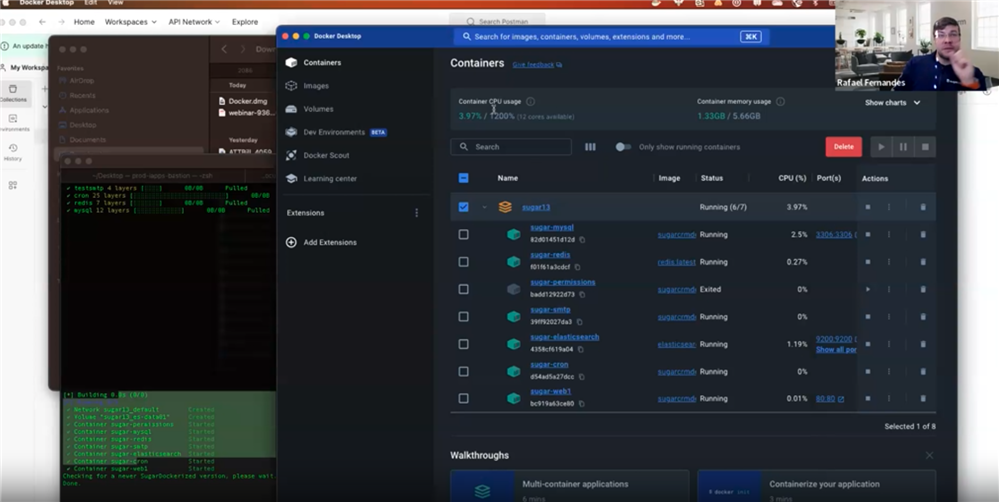
Working with fresh installs and SugarCloud backups
Rafael also demonstrated how you can do a fresh install using one of our Developer Builds or a Sugar Enterprise downloads for doing add-on development.
Or how you can take a back-up from a SugarCloud and run it locally in your Docker container, with all the data intact, so you can debug tricky issues or develop customizations for a SugarCloud instance.
Session Recording
This session was recorded on December 6th. Here is the recording and slides.
Let us know how we are doing!
We want our Developer Office Hours sessions to be relevant and valuable. Please provide feedback so we can continue to improve and better serve you!
Share your feedback with this short survey.
Next Session Sign-Up
We are skipping January 2024. The next session will be on February 7th, 2024.
Please register for the Office Hours series so you don’t miss a session.
Developer Office Hours are (typically) held on the first Wednesday of every month at 10 a.m. ET / 7 a.m. PT.

