

This part is focused on AWS setup for Fraud Detection, where you will create a new free-tier AWS account (if you don’t already have one), create a fraud-detection user, create IAM rules and permissions, add S3 buckets to store our datasets, create, train, deploy and test your models.
We will also walk through all the manual processes involved in this setup as well as a NodeJS project that creates and tears down automatically all the infrastructure created by this exercise.
Step 1: Sign-up with AWS (free tier account)
You must have an account with AWS to continue. Amazon provides a free tier AWS account for 12 months for most of its services. For Fraud Detection, you do have a 2 months free trial even for existing AWS customers. You can follow this step-by-step guide to create your free tier account with AWS.
Step 2: Setup the IAM User, Group, and Permissions
With your newly minted AWS account, your email/password will give you root access to AWS resources pretty much like a root user on a Linux environment. It’s too much power for our day-by-day activities therefore this exercise. It is a best practice to create an individual user and assign it only the permissions and/or groups necessary.
The following permission policies will allow you full access (create, delete, update) to Fraud Detector, S3 and IAM services. These are needed if you plan to automate the setup using the NodeJS app described later. However if you prefer to go with manual steps, then IAM access can be left out.
You should create a new IAM User and a IAM Group with these specific permissions:
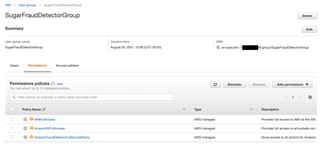
- AmazonFraudDetectorFullAccessPolicy - Gives access to all actions for Amazon Fraud Detector
- AmazonS3FullAccess - Provides full access to all buckets via the AWS Management Console
- IAMFullAccess - Provides full access to IAM via the AWS Management Console
Note giving Full Access to those services (FraudDetector, S3 and IAM) is not ideal. Normally you would provide minimum access and grant it as needed. You should review with your security team those permissions before implementing it in production.
You can follow the step-by-step screens to create and give permissions to your user for either manual or automated AWS setup.
1- Add a User with programmatic access
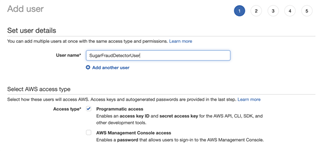
2 - Create and Add this User to a group
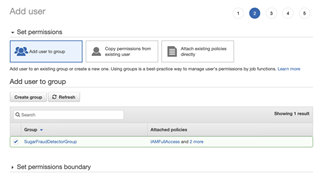
3 - When you click on “Create Group”, make sure you add the following “Permissions policies”:
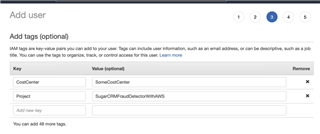
3 - (Optional) Add tags (for all our AWS work, we will use these two tags everywhere)
4 - Review your user creation and make sure the group is assigned. It’s a common mistake to miss checking the box on page 2.
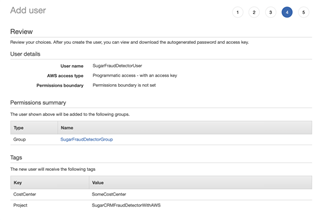
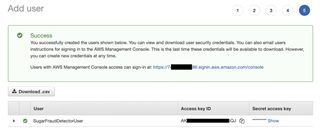
5 - After a user is added, you are provided with an access key ID and secret access key. Save them in a safe place! You will need to use them in the NodeJS app since it gives us temporary access to AWS resources to create, delete and update as described earlier.
Amazon Fraud Detector Overview
This is a fully managed service by Amazon that uses your data to predict and potentially block fraudulent credit card transactions and fake account signups. It uses machine learning (ML) algorithms on top of your clean historical data. If you didn’t read it, please review how to build and gather historical data in the previous post. At this point all you should need to do is train, test and deploy your model.
You need to thoroughly understand a few Fraud Detector concepts and how they operate before continuing.
Workflow
This is how you need to setup AWS fraud detection leveraging the IAM setup from earlier:
- Create an S3 bucket and upload your datasets
- Create a new service role and grant permission to this S3 bucket to Fraud Detection service (you can do that while creating a model)
- Create your fraud detection resources (entity types, variables, labels, event types, outcomes)
- Define, configure and train your model
- Review your model’s performance and deploy
- Create a detector and define your prediction rules and outcomes
- Test the predictions
Model Definition
A model is the output of a machine learning algorithm run on datasets. It has rules, numbers and other fancy data structures required to make predictions.
Amazon uses their own machine learning algorithms on their supervised model called Online Fraud Insights. That’s the type of model you will create and train, so please take some time to learn about it.
You will receive these scores from this service and those will be used in Sugar (along with the outcomes) for our FraudDetector Module.
Model Metrics
Model Metrics are used to monitor and measure the performance of a model for Amazon Fraud Detector.
Usually when building a machine learning model, you need two different datasets. One for training and another one for testing your model. With Amazon Fraud Detector that is not necessary as it reserves 15% of your dataset as their test data. That validation (training vs test) will be available as Model Performance Metric.
A good starting point and good metric I found useful is the “area under the curve” (AUC), which ranges from 0 to 1. As per Amazon’s definition, “Area under the curve (AUC) – Summarizes TPR and FPR across all possible model score thresholds. A model with no predictive power has an AUC of 0.5, whereas a perfect model has a score of 1.0.”
As an example, our dataset for credit card transactions has been scored as AUC 0.99, which can successfully catch 97.1% of fraudulent events out of 500.

If your model hasn’t gotten AUC with a minimum of 0.5, go back and review the quality of your historical data. You may need to gather some more data and retrain your model.
Get Fraud Detector Prediction
Amazon Fraud Detector service provides you with an easy tool to test and get predictions from your model without building or triggering their API. This can be helpful for making sure your model is really performing well.
In order to test with the API, you need test event data. For example, one fraud event and one legit event. By following these easy steps, you should be presented with a result like this:
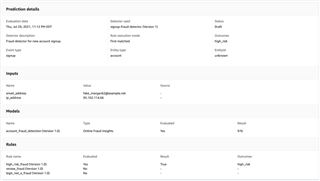
It presents you with prediction details, your input data, the resulting score from your model (as a matter of fact, the model attached to that detector), and the rules and outcome that have been evaluated.
All predictions will be available in the “Search past prediction” menu item, very helpful to audit calls to this service and its outcomes, even the ones triggered by Sugar via SDK.
Detector Definition
Detectors are “detection logic builders”. They are based on rules and outcomes, for your model’s scoring results. Detectors also expose publicly accessible APIs, so you can think of them as your API Gateway for Amazon Fraud Detector service.
That detection logic is evaluated for each “GetEventPrediction” API call synchronously. When the detector receives an event, it runs through the model and gets a prediction score/insight, and returns the outcome along with the score.
Versioning is quite important here, we will have to pass the version as argument to most of our API calls, for detector version, we can only have one ACTIVE version.
Console Setup
Amazon folks have put together a step by step guide to accommodate the entire workflow with screenshots and very useful material along with explanations and examples. If you are a console person, please go ahead and follow that guide. Make sure you understand how to clean up those resources as well since leaving them deployed might incur costs when your free tier expires.
Automated Setup
We have come up with a NodeJS project that automates that workflow by creating and tearing down resources. Our Node app uses a standard architecture that should be really easy to follow and most importantly, it handles all dependencies required while setting up AWS.
Why didn’t we use CloudFormation? The reason was, at the time of this writing, there is not an easy way of waiting for resources, specially model training to become available then continue with its dependencies. There are ways of achieving this goal, but this is not the purpose of this series.
The code is available in GitHub and it is open source.
SugarFraudDetector Configuration
There are two types of configuration for this project to work, one contains AWS API’s specifics such as key and secret and another one is where you set your Fraud Detector metadata used to setup/teardown resources in AWS.
If you don't have NodeJS installed please refer to their Install Node guide. As a reference, for this project, we used NodeJS v16.5.0.
As in any NodeJS application, you need to install all dependencies (AWS, debug, dotenv, full list is in the package.json), by running the following command:
npm install
Config file (.env)
In this configuration file .env, you will add AWS API’s specific configuration. AWS access and secret keys, for instance, were provided in step five when you created a new user.
Copy and paste them on these placeholders down below as well as choose a region where you’d like to have your Fraud Detection setup.
If you don't have or lost your access/secret keys then check this post. It will help you generate new ones.
At the time of writing, Amazon Fraud Detector is available in the US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), Asia Pacific (Singapore) and Asia Pacific (Sydney) AWS regions.
AWS_ACCESS_KEY_ID=<YOUR KEY>
AWS_SECRET_ACCESS_KEY=<YOUR SECRET>
AWS_API_REGION=us-east-1
AWS_DEFAULT_REGION=us-east-1
DEBUG=sugar:frauddetector:*
The Debug framework allows you to debug specific classes, all classes, or none. Instructions for configuring it are here. I do suggest you leave it on so you know what is happening since this is a one time thing.
Config file
This file, ./src/config/index.js, contains our project’s metadata used to create and teardown resources in AWS. It is self-explanatory and has been coded in a resourceful way so you can just update or adapt it for your needs.
In the fraudDetector section, you will notice definitions for account and transaction, each with its own metadata where you can adapt the names and descriptions for those resources.
In the variables section, you have all the fields used to train your model and that are used in your request events when asking for predictions from the AWS service. Important to note that the name has to match the column name in your CSV file (you don't need to declare [EVENT_TIMESTAMP and EVENT_LABEL]) but they are required in your CSV as mentioned in the previous post.
Create App
SugarFraudDetector has an app called “create” that reads your config metadata and builds all necessary resources respecting their dependencies and awaits them to deploy.
If you enabled debug, you will be able to follow the logs as it interacts with AWS and create your resources. You could also open your AWS console and see them being created as well and make sure you are in the same region as you specified in the config file. If you don't, you will not see your resources.
Run the following command to start the process:
npm run create
Teardown App
Tearing down all the resources is as important if not more so than creating them. This is how you stop paying for your resources! If you’re not in the trial period of course.
SugarFraudDetector has an app called “teardown” which tears down all resources created from your config metadata, as in creating them, there are dependencies in the service we have to respect, for example, cannot delete resources that are still attached to a model and rules still attached to detectors.
This app also provides an extensive logging to follow while it tears down and awaits those resources to be terminated, all you have to do is run the following command to start the teardown process: npm run teardown
Sometimes resources take longer to tear and throw errors therefore its dependencies cannot be removed. If that’s the case then all you have to do is to re-execute the command until everything is clear. No harm will be done by executing it multiple times.
Note: if you’ve created new resources or updated your config after its creation, you will have to terminate them yourself, the script will not delete something it hasn’t created.
Final words
Please take some time to review Security , Quotas and Monitoring on Amazon Fraud Detector as these topics are very important when you're preparing to go live in production.
This concludes your Data and AWS preparedness of this series, next, you will integrate Amazon Fraud Detector with an Ecommerce application and SugarCRM.
References
https://aws.amazon.com/fraud-detector/
https://towardsdatascience.com/machine-learning-general-process-8f1b510bd8af